Fraudulent healthcare claims increase the burden to society.
Therefore healthcare fraud detection is now becoming more and more important.
Generally, healthcare frauds are not obvious and thus difficult to detect.
The followings are typical examples of healthcare fraud techniques used by
health care providers and patients;
Statistical healthcare fraud detection techniques
The net effect of excessive fraudulent claims is excessive billing amounts,
higher per-patient costs, excessive per-doctor patients, higher per-patient tests,
and so on. This excess can be identified using special analytical tools.
Provider statistics include;
- Total amount billed.
- Total number of patients.
- Total number of patient visits.
- Per-patient average billing amounts.
- Per-patient average visit numbers.
- Per-patient average medical tests.
- Per-patient average medical test costs.
- Per-patient average prescription ratios (of specially monitored drugs).
- and many more.
Analytic Healthcare Fraud Detection Methods
Healthcare fraud detection involves account auditing and detective investigation.
Careful account auditing can reveal suspicious providers and
policy holders. Ideally, it is best to audit all claims one-by-one
carefully. However,
auditing all claims is not feasible by any practical means.
Furthermore, it's very difficult to audit providers without
concrete smoking clues.
A practical approach is to develop short lists for scrutiny
and perform auditing on providers and patients in the short lists.
Various analytic techniques can be employed in developing audit short
lists. Keep in mind that excessive fraudulent claims lead
deviations in aggregate claims statistics. In addition, fraudulent claims
often develop into patterns that can be detected using predictive models!
Statistical listings of risky providers
When abusive claims are repeated frequently, the consequent
is higher provider statistics. Various provider statistics can
be used to identify fraudulent claims.
For instance, audit short-lists may include the followings;
- Doctors who treated whopping, say, 50+ patients in a day.
- Providers administering far higher rates of tests than others.
- Providers costing far more, per patient basis, than others.
- Providers with high ratio of distance patients.
- Providers prescribing certain drugs at higher rate than others.
- and so on.
It is noted that statistical analytic techniques can reveal
excessive providers who might be outright stupid!
But it will be difficult to identify modest level fraud activities.
Predictive Modeling and Deep Learning
Predictive models can predict potential fraudulent claims and providers.
Predictive models can be developed using information described above.
However it is difficult to obtain training historical data as most
fraudulent claims may have not been discovered!
To overcome this limitation, predictive scoring models using known cases
can be developed. Then these models are used to predictict fraud scores to unknown data
to find highest potential fraud cases.
(Predictive modeling tips)
Large neural networks with a large number of input and hidden nodes
lead to overfitting. Large networks, especially with small training datasets,
can remember individual records. This is no good predictive model.
A better way is to decompose problems into multiple smaller neural networks with
a small number of input and hidden layer nodes, each network predicting one type of
frauds. Then integerate them with higher level neural networks or use
rules to combine them.
For more on this deep learning style method, read
Rule Engine with Machine Learning, Deep Learning, Neural Network.
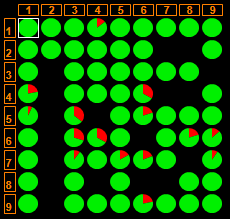
Clustering can discover similar fraud cases!
Clustering can be used to find more fraud cases that are similar to known cases.
The following figure shows CMSR Data Miner neural clustering.
It has 9x9 (=81) cells. Each cell contains providers with "similar" attributes. Round figures are
pie charts. Red portions represent fraudulent cases. Green areas are status-unknown portions. Providers within cells with red portions
might be hidden cases that may need investigation;