|
|
||||||||||||||
Direct Mail Marketing - Catalog salesIn direct mail marketing, it is important to have well-focused targeted marketing strategy. The problem of direct mail marketing is that it borders around illegal spam e-mails (or junk mails) and illegitimate business activities. Modern-day computer and telecommunication technology enables direct mail marketers to send millions of unsolicited mails to unwanted customers very easily. This type of commercial practice is not only undesirable to customers but also harmful to businesses that send such information. First, sending spam and junk mails may not be legal by laws. Second, sending emails may cost very little. However, sending postal mails and SMS messages can cost significantly. Furthermore, sending catalog may cost even more. Third, keep sending mails that are not of interest to customers can turn off customers, losing permanently. For example, customers may include you to spam filters! Therefore, there are strong reasons to keep catalog mailing to a minimum.
What customer information is used in Targeted Mail Marketing?Targeted direct mail marketing techniques described here are well-suited to companies with a large number of direct customers or data providers with a large number of potential customers. Customer information that can be used in selection of customers may include the followings;
In addition, RFM information can be added to the list;
Hierarchical segm
|
||||||||||||||
What's wrong with classification methods?Intuitively, classification predictive modeling is a very appealing concept for direct mail marketing. However, there is a serious drawback in applying classification techniques (such as decision tree, SVM, etc) to direct mail marketing. The problem lies with the fact that response rate is extremely low, as some survey suggests about 2%! Developing predictive models with skewed data is very difficult. Decision trees develop predictive models through segmenting populations into smaller groups repeatedly. It uses the dominant value (or most frequent value) of each segment as the predicted value for the segment. Dominant values are the values represented by over 50% segment population. Given the nature of low responses, it is possible that no segments may contain responses in excess over 50%! Even they exist, they may be slightly over 50%! Segments in which 49% customers have responded will be predicted as "not responded", although they are very highly responsive groups! This type of models will have very low accuracy in predicting responsive customers as "responded". To overcome this problem, some may be tempted to use tricks by introducing extra instances. However, such tricks will necessarily distort overall representation of population. |
Response scoring using Neural network
Generally, catalog sales is a very low response-rate event. Developing predictive models on skewed data is extremely difficult and therefore models can be inherently un-reliable. Neural network provides a way that can overcome this difficulty and identify positive responses in high accuracy. This method can be implemented as follows;
- Build a neural network model that predicts responses (or sales profit amounts) based on a previous campaign result. Note this may be from sampling campaigns. The model will under-predict response values as most customers will have zero response values. None the less, it will score highly for potential respondents with high consistency.
- Apply the model to the same previous campaign dataset to predict responses. That is, to compute "customer response scores".
-
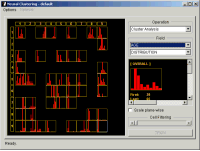
Encode customers of the previous campaign as "responded" and "not-responded". Using CMSR dimensional histogram charts, analyze distribution of predicted default amounts over the encoded dimension. You will see high concentration of responsive customers in higher score intervals. The following figures show an example. Reds are customers who have responded. They are concentrated at high score ranges.
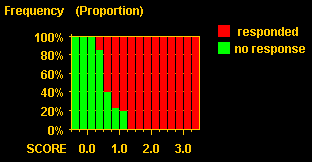
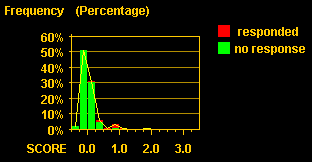
The original score values ranged 0 ~ 4. Notice that the figure shows slightly under-valued than the original.
- Apply the neural network model to the current customer dataset. It is recommended that time-variant information is based on the date of mailing. You can select customers having scores beyond a certain threshold.
-
The scores can be used for response capture and profit analysis.
The key to success is the neural network scoring. Accurate customer scoring will ensure that most of potential responses will be captured at a minimal cost.
Neural Clustering Segmentation
Clustering groups similar customers together into segments. The rationale behind clustering is that customers with similar attributes often exhibit similar patterns in purchasing behaviors. If customers of a certain group responded positively in previous campaigns, the group is likely to produce similar positive outcome in future marketing campaigns. This approach involves clustering customers into segments of having similarity. If there are segments showing high response rate in previous campaigns, customers of the segments will be selected in new campaigns.
CMSR Neural Clustering is well suited for this. Neural clustering is based on neural network known as Self Organizing Maps (SOM). SOM is how our brains process information and recognize patterns and features using the technique called competitive learning. Neural clustering has magical power as in the way that your eyes recognize similar patterns! As shown in the following figures, neural clustering organizes similar customers into two dimensional grid cells in such a way that customers in the same cells have very similar attributes. In additions, customers at nearby cells have similar attributes. That is, closer the cells, more similar the customers are. The following charts show an example of distribution of customers in segments (i.e., cells). The left shows pie charts for categorical variables. The middle is histograms for numerical variables. Intuitively, the left figure shows that customers of the same values for the variable shown are clustered into the same cells or spread over nearby cells. Note that all cells have single color pie charts, which means cells contain objects of the same categorical value only. Also notice that nearby cells have the same color pie charts. Though less obvious in the middle figure, close examination reveals that nearby cells have similar numerical value distribution.
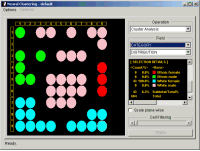
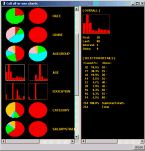
For more information, click Neural Clustering.
|
Caveat |
Hottest Segment Profiling
It is common to see that 80% of positive responses are from 20% of customer groups. Even better case can be 90% coming from 10% of customer groups. Instead of unpredictable predictive modeling, profiling those major groups from demographic (and geographic and psychographic) information and mailing to customers who belong to the groups can capture most customers who may respond your marketing campaigns. It can minimize the loss of sales from not sending catalogs, which is a very expensive opportunity cost. In addition, mailing cost will be significantly reduced as well.
For more information, click Hotspot Analysis.
Rule-based Pinpoint Precision MarketingDirect catalog marketing tends to be most effective for selling special products to special customer segments at special prices. Normally, straightforward predictive modeling and segmentation does not work well or at best provides marginal improvement. There are various reasons. For example, predictive modeling and segmentation is based on past data and therefore predicts past patterns of past campaigns. Future may be very different. Such patterns cannot be captured by predictive modeling alone. CMSR rule-based modeling environment (RME) is a platform where complex rules can be combined with advanced predictive modeling. Pinpoint precision marketing plans can be developed and executed with the platform. New emerging patterns are captured manually and combined with predictive models which represent past customers' buying patterns. For more about RME, please read Predictive Modeling Software. |
Product buying pattern analysis and Cross-selling
Customers tend to buy variety of products from the same businesses. Analyzing such information can reveal valuable business opportunities in various way. The following chart shows customer purchasing behaviors;
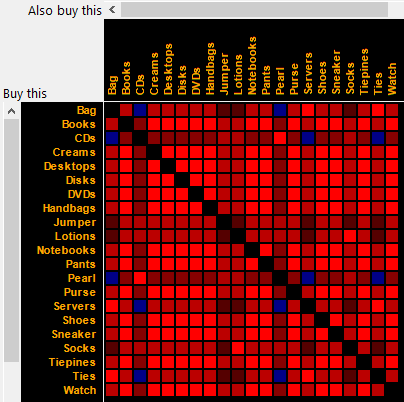
Cells in red color indicate that there is positive association between two products. That is, when customers buy one product, they tend to buy the other product as well. Cells in blue color indicate the opposite. When customers buy one product, they tend to not buy the other product. Brightness of cells indicates the relative strength of relationships.
Product purchasing patterns can be used for cross-sell marketing. In addition, it can be very useful information in catalog design. Placing products with strong associations together or nearby may improve overall sales!
For information about software used here, please read Data Mining Software. Software download is available from the page.
For information about predictive modeling, please read Predictive Modeling Software Tools.
|
|